On the evening of the last Wednesday in September, we had our first CaSA, Computer and System Architecture Unraveled, event. CaSA is a meetup in Kista (Sweden) for people interested in computer architecture, system architecture, and how software and hardware interact down towards the lower levels of the stack. The topic for the inaugural event was “Core Count Explosion: A Challenge for Hardware and Software”, and it was great in some many ways!
Continue reading “The first Computer and System Architecture Unraveled Event in Kista – Great Speakers, Great Fun!”Category: multicore computer architecture
What’s in a Kilowatt Hour?
The current price spikes for electricity in Europe has driven a new interest in saving energy, and part of doing that is to understand just how much energy different things use. I realized while I knew that modern LED lights are magically efficient, just how much electricity is used by other machines? No idea! So, I set out to find some examples the utility you get from a one kilowatt hour of electricity.
Updated in November 2022 with additional data.
Continue reading “What’s in a Kilowatt Hour?”gem5 Full Speed Ahead (FSA)
I had many interesting conversations at the HiPEAC 2017 conference in Stockholm back in January 2017. One topic that came up several times was the GEM5 research simulator, and some cool tricks implemented in it in order to speed up the execution of computer architecture experiments. Later, I located some research papers explaining the “full speed ahead” technology in more detail. The mix of fast simulation using virtualization and clever tricks with cache warming is worth a blog post.
SiCS Multicore Day 2016 – In Review
![]() The SiCS Multicore Day took place last week, for the tenth year in a row! It is still a very good event to learn about multicore and computer architecture, and meet with a broad selection of industry and academic people interested in multicore in various ways. While multicore is not bright shiny new thing it once was, it is still an exciting area of research – even if much of the innovation is moving away from the traditional field of making a bunch of processor cores work together, towards system-level optimizations. For the past few years, SiCS has had to good taste to publish all the lectures online, so you can go to their Youtube playlist and see all the talks for free, right now!
The SiCS Multicore Day took place last week, for the tenth year in a row! It is still a very good event to learn about multicore and computer architecture, and meet with a broad selection of industry and academic people interested in multicore in various ways. While multicore is not bright shiny new thing it once was, it is still an exciting area of research – even if much of the innovation is moving away from the traditional field of making a bunch of processor cores work together, towards system-level optimizations. For the past few years, SiCS has had to good taste to publish all the lectures online, so you can go to their Youtube playlist and see all the talks for free, right now!
Clocks or Cores? Choose One
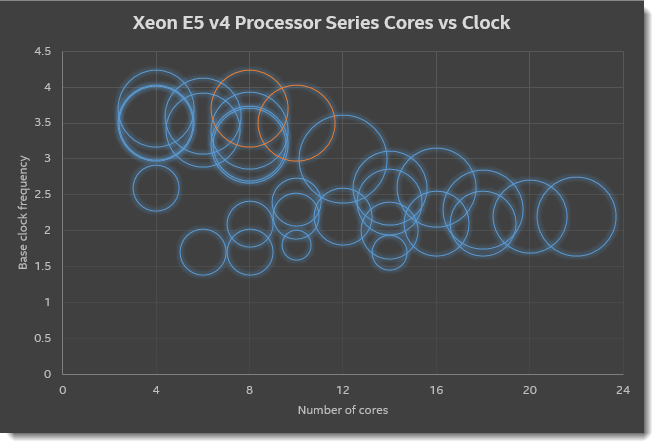
Once upon a time, when multicore processors were novelties, multicore was motivated by the simple fact that it was impossible to keep raising the clock frequency of processors. More “clocks” simply would result in an overheated mess. Instead, by adding more cores, much more performance could be obtained without having to go to extreme frequencies and power budgets. The first multicore processors pretty much kept clock frequencies of the single-core processors preceding them, and that has remained the mainstream fact until today. Desktop and laptop processors tend to stay at 4 cores or less. But when you go beyond 4 cores, clock frequencies tend to start to go down in order to keep power consumption per package under control. A nice example of this can be found in Intel’s Xeon lineup.
Continue reading “Clocks or Cores? Choose One”
Hardware debug and measurement in the IBM POWER8

I have read some recent IBM articles about the POWER8 processor and its hardware debug and trace facilities. They are very impressive, and quite interesting to compare to what is usually found in the embedded world. Instead of being designed to help with software debug, it seems the hardware mechanisms in the Power8 are rather focused on silicon bringup and performance analysis and verification in IBM’s own labs. As well as supporting virtual machines and JIT-based systems!
Continue reading “Hardware debug and measurement in the IBM POWER8”
Wind River Blog: Simics 5 Multicore Accelerator Explained
![]() While I was on vacation, Wind River published a blog post I wrote about the new multicore accelerator feature of Simics 5. The post has some details on what we did, and some of the things we learnt about simulation performance.
While I was on vacation, Wind River published a blog post I wrote about the new multicore accelerator feature of Simics 5. The post has some details on what we did, and some of the things we learnt about simulation performance.
Thin Phone, Fat Core
![]() When mobile phones first appeared, they were powered by very simple cores like the venerable ARM7 and later the ARM9. Low clock frequencies, zero microarchitectural sophistication, sufficient for the job. In recent years, as smartphones have come into their own as the most important computing device for most people, the processor performance of mobile phones have increased tremendously. Today, cutting-edge phones and tablets contain four or eight cores, running at clock frequencies well above 2 gigahertz. The performance race for most of the market (more about that in a moment) was mostly about pushing higher clock frequencies and more cores, even while microarchitecture was left comparatively simple. Mobile meant “fairly simple”, and IPC was nowhere near what you would get with a typical Intel processor for a laptop or desktop.
When mobile phones first appeared, they were powered by very simple cores like the venerable ARM7 and later the ARM9. Low clock frequencies, zero microarchitectural sophistication, sufficient for the job. In recent years, as smartphones have come into their own as the most important computing device for most people, the processor performance of mobile phones have increased tremendously. Today, cutting-edge phones and tablets contain four or eight cores, running at clock frequencies well above 2 gigahertz. The performance race for most of the market (more about that in a moment) was mostly about pushing higher clock frequencies and more cores, even while microarchitecture was left comparatively simple. Mobile meant “fairly simple”, and IPC was nowhere near what you would get with a typical Intel processor for a laptop or desktop.
Today, that seems to be changing, as the Nvidia Denver core and Apple’s Cyclone core both go the route of a few fat cores rather than many thin cores.
David May on Multicore: Heterogeneity not Needed
Via the EETimes, I found a very interesting talk by Bristol professor David May, presented at the 4th Annual Bristol Multicore Challenge, in June of 2013. The talk can be found as a Youtube movie here, and the slides are available here. The EETimes focused on the idea to cut down ARM to be really RISC, but I think the more interesting part is Professor May’s observations on multicore computing in general, and the case for and against heterogeneity in (parallel) computers.
Continue reading “David May on Multicore: Heterogeneity not Needed”
Two Cores, Four Cores, Eight Cores – Mobile Variety
 Probably thanks to the yearly Mobile World Congress, there have been a slew of recent announcements of mobile application processors recently. Everything is ARM-based, but show quite some variety in the CPU core configurations used. Indeed, I think this variety has something to say on the general state of multicore.
Probably thanks to the yearly Mobile World Congress, there have been a slew of recent announcements of mobile application processors recently. Everything is ARM-based, but show quite some variety in the CPU core configurations used. Indeed, I think this variety has something to say on the general state of multicore.
Continue reading “Two Cores, Four Cores, Eight Cores – Mobile Variety”
SiCS Multicore Day 2012
![]() The 2012 edition of the SiCS Multicore Day was fun, like they have always been in the past. I missed it in 2010 and 2011, but could make it back this year. It was interesting to see that the points where keynote speakers disagreed was similar to previous years, albeit with some new twists. There was also a trend in architecture, moving crypto operations into the core processor ISA, that indicates another angle on the hardware accelerator space.
The 2012 edition of the SiCS Multicore Day was fun, like they have always been in the past. I missed it in 2010 and 2011, but could make it back this year. It was interesting to see that the points where keynote speakers disagreed was similar to previous years, albeit with some new twists. There was also a trend in architecture, moving crypto operations into the core processor ISA, that indicates another angle on the hardware accelerator space.
Nvidia “Kal-El” Variable SMP
![]() Nvidia recently announced that their already-known “Kal-El” quad-core ARM Cortex-A9 SoC actually contains five processor cores, not just four as a “normal” quad-core would. They call the architecture “Variable SMP”, and it is a pretty smart design. The one where you think, “I should have thought of that”, which is the best sign of something truly good.
Nvidia recently announced that their already-known “Kal-El” quad-core ARM Cortex-A9 SoC actually contains five processor cores, not just four as a “normal” quad-core would. They call the architecture “Variable SMP”, and it is a pretty smart design. The one where you think, “I should have thought of that”, which is the best sign of something truly good.
Memory Models: x86 is TSO, TSO is Good
![]() By chance, I got to attend a day at the UPMARC Summer School with a very enjoyable talk by Francesco Zappa Nardelli from INRIA. He described his work (along with others) on understanding and modeling multiprocessor memory models. It is a very complex subject, but he managed to explain it very well.
By chance, I got to attend a day at the UPMARC Summer School with a very enjoyable talk by Francesco Zappa Nardelli from INRIA. He described his work (along with others) on understanding and modeling multiprocessor memory models. It is a very complex subject, but he managed to explain it very well.
SecurityNow on Randomness
 Episodes 299 and 301 of the SecurityNow podcast deal with the problem of how to get randomness out of a computer. As usual, Steve Gibson does a good job of explaining things, but I felt that there was some more that needed to be said about computers and randomness, as well as the related ideas of predictability, observability, repeatability, and determinism. I have worked and wrangled with these concepts for almost 15 years now, from my research into timing prediction for embedded processors to my current work with the repeatable and reversible Simics simulator.
Episodes 299 and 301 of the SecurityNow podcast deal with the problem of how to get randomness out of a computer. As usual, Steve Gibson does a good job of explaining things, but I felt that there was some more that needed to be said about computers and randomness, as well as the related ideas of predictability, observability, repeatability, and determinism. I have worked and wrangled with these concepts for almost 15 years now, from my research into timing prediction for embedded processors to my current work with the repeatable and reversible Simics simulator.
Wind River Blog: True Concurrency is Different
![]() I have another blog up at Wind River. This one is about multicore bugs that cannot happen on multithreaded systems, and is called True Concurrency is Truly Different (Again). It bounces from a recent interesting Windows security flaw into how Simics works with multicore systems.
I have another blog up at Wind River. This one is about multicore bugs that cannot happen on multithreaded systems, and is called True Concurrency is Truly Different (Again). It bounces from a recent interesting Windows security flaw into how Simics works with multicore systems.